lunes, 31 de octubre de 2011
domingo, 30 de octubre de 2011
2nd Theoretical Assignment - File Systems
Hi, in this entry i'm going to talk about performance of file systems.
As we already know a File System is a huge collection of directories and files which save all kind of information. File Systems are organized by directories which in turn can contain besides files, other directories or sub-directories.
A way of organizing a file system may be:
The system name for a file must be unique in the file system. In hierarchical file systems, the system name for a file is usually the "trajectory name" from the 'root directory' to the file.
Example: /home/ubuntu/myfile.txt
Directories in UNIX systems are organized keeping certain hierarchy as we can see in the following schematic picture:
 Some utilities of File Systems according to Wikipedia are:
Some utilities of File Systems according to Wikipedia are:
File systems include utilities to initialize, alter parameters of and remove an instance of the filesystem. Some include the ability to extend or truncate the space allocated to the file system.
Directory utilities create, rename and delete directory entries and alter metadata associated with a directory. They may include a means to create additional links to a directory (hard links in Unix), rename parent links (".." in Unix-like OS), and create bidirectional links to files.
File utilities create, list, copy, move and delete files, alter metadata. They may be able to truncate data, truncate or extend space allocation, append to, move, and modify files in-place. Depending on the underlying structure of the filesystem, they may provide a mechanism to prepend to, or truncate from, the beginning of a file, insert entries into the middle of a file or deletion entries from a file.
Also in this category are utilities to free space for deleted files if the filesystem provides an undelete function.
Some filesystems defer reorganization of free space, secure erasing of free space and rebuilding of hierarchical structures. They provide utilities to perform these functions at times of minimal activity. Included in this category is the infamous defragmentation utility.
There are two general strategies to store a 'n' bytes file.
1. Assign 'n' consecutive bytes of disk space.
Some of the most important features of files system utilities involve supervisory activities which may involve bypassing ownership or direct access to the underlying device. These include high performance backup and recovery, data replication and reorganization of various data structures and allocation tables within the filesystem.
Example of emulating a defragmentation algorithm:
http://forums.devshed.com/c-programming-42/defragmentation-algorithm-757280.html
References:
http://en.wikipedia.org/wiki/File_system
http://www.cecalc.ula.ve/bioinformatica/UNIX/node10.html
As we already know a File System is a huge collection of directories and files which save all kind of information. File Systems are organized by directories which in turn can contain besides files, other directories or sub-directories.
A way of organizing a file system may be:
- Using a 'root' to signal where in the disk the 'root directory' starts.
- The 'root directory' points to 'user directories'
- An 'user directory' contains an entry for every file
- The file names need to be unique inside a certain user directory.
The system name for a file must be unique in the file system. In hierarchical file systems, the system name for a file is usually the "trajectory name" from the 'root directory' to the file.
Example: /home/ubuntu/myfile.txt
Directories in UNIX systems are organized keeping certain hierarchy as we can see in the following schematic picture:

File systems include utilities to initialize, alter parameters of and remove an instance of the filesystem. Some include the ability to extend or truncate the space allocated to the file system.
Directory utilities create, rename and delete directory entries and alter metadata associated with a directory. They may include a means to create additional links to a directory (hard links in Unix), rename parent links (".." in Unix-like OS), and create bidirectional links to files.
File utilities create, list, copy, move and delete files, alter metadata. They may be able to truncate data, truncate or extend space allocation, append to, move, and modify files in-place. Depending on the underlying structure of the filesystem, they may provide a mechanism to prepend to, or truncate from, the beginning of a file, insert entries into the middle of a file or deletion entries from a file.
Also in this category are utilities to free space for deleted files if the filesystem provides an undelete function.
Some filesystems defer reorganization of free space, secure erasing of free space and rebuilding of hierarchical structures. They provide utilities to perform these functions at times of minimal activity. Included in this category is the infamous defragmentation utility.
There are two general strategies to store a 'n' bytes file.
1. Assign 'n' consecutive bytes of disk space.
- Downside: If a file size increases, it will probably move in the disk, which can affect performance.
- Generally file systems use this strategy with fixed size blocks.
Some of the most important features of files system utilities involve supervisory activities which may involve bypassing ownership or direct access to the underlying device. These include high performance backup and recovery, data replication and reorganization of various data structures and allocation tables within the filesystem.
Example of emulating a defragmentation algorithm:
http://forums.devshed.com/c-programming-42/defragmentation-algorithm-757280.html
References:
http://en.wikipedia.org/wiki/File_system
http://www.cecalc.ula.ve/bioinformatica/UNIX/node10.html
2nd Theoretical Assignment - Page Replacement
Hi there, in this post I will explain how the page replacement algorithms work.
So first, what is the page replacement algorithm for?
In a computer operating system that uses paging for virtual memory management, page replacement algorithms decide which memory pages to page out (swap out, write to disk) when a page of memory needs to be allocated. - Wikipedia
In our nachos, the page replacement algorithm will decide which page is going to be swapped out in order to allocate a new one. For this, Martin C. Rinard mentions two algorithms in his notes: FIFO, and LRU.
FIFO
FIFO means, like many of you may already know, First-In First-Out, so this algorithm is going to swap the first page brought into memory, regardless of whether it has been accessed recently or not.
An example would be:
Sequence: 1, 2, 3, 1, 4 (Using a 3 sized memory)
1-> [1]
2->[1, 2]
3->[1, 2, 3]
1->[1, 2, 3] #1 is accessed again
4->[2, 3, 4] #And yet is swapped in the next turn
This is a downside of the algorithm, it may eject a heavily used page.
A pseudo-code for this algorithm would be:
So first, what is the page replacement algorithm for?
In a computer operating system that uses paging for virtual memory management, page replacement algorithms decide which memory pages to page out (swap out, write to disk) when a page of memory needs to be allocated. - Wikipedia
In our nachos, the page replacement algorithm will decide which page is going to be swapped out in order to allocate a new one. For this, Martin C. Rinard mentions two algorithms in his notes: FIFO, and LRU.
FIFO
FIFO means, like many of you may already know, First-In First-Out, so this algorithm is going to swap the first page brought into memory, regardless of whether it has been accessed recently or not.
An example would be:
Sequence: 1, 2, 3, 1, 4 (Using a 3 sized memory)
1-> [1]
2->[1, 2]
3->[1, 2, 3]
1->[1, 2, 3] #1 is accessed again
4->[2, 3, 4] #And yet is swapped in the next turn
This is a downside of the algorithm, it may eject a heavily used page.
A pseudo-code for this algorithm would be:
fifo(page):
#If the memory is not full yet
if len(memory) < memory_size:
#And the page is not already in memory
if page not in memory:
#Add the page to memory
memory.append(page)
#If the memory is full
elif len(memory) == memory_size:
#And the page is not already in memory
if page not in memory:
#swap out the first added page ( index 0 on the queue)
swap_out = memory.pop(0)
#Add the page to memory at the end
memory.append(page)

LRU, Least Recently Used, works as it sounds, it will swap out the least page used. For this the algorithm uses a queue, in which the pages brought to memory will be added to the beginning of the queue. When a page fault occurs, the algorithm swaps out the last page on the queue.
Sequence: 1, 2, 3, 1, 4 (Using a 3 sized memory)


1->[1] - [1]
2->[1, 2] - [2, 1]
3->[1, 2, 3] - [3, 2, 1]
1->[1, 2, 3] - [1, 3, 2] # 1 is accessed, the queue updates
4->[1, 4, 3] - [4, 1, 3] #a page fault occurs, 2 is the least recently used, so it's ejected.
A pseudo-code for this algorithm would be:
LRU(page):
#If the memory is not full yet.
if len(queue) < memory_size:
#And the page is not already in the queue
if page not in queue:
#Add the page to the beginning of the queue.
queue.insert(0, page)
#else if its already in the queue
else:
#Pop the page out, and add it at the beginning
queue.pop(queue.index(page))
queue.insert(0, page)
#If the memory is already full
if len(queue) == memory_size:
#And the page is not in the queue
if page not in queue:
#swap out the last page in the queue, and add the new one to the beginning
swap_out = queue.pop()
queue.insert(0, page)
#Else if it's already in the queue
else:
#Pop the page out, and add it at the beginning
queue.pop(queue.index(page))
queue.insert(0, page)

LRU Vs FIFO
To test the algorithm, a sequence of 20 random pages were used to obtain averages between 100 samples. Five different pages were used(from 1 to 5).

So, according to this, in average FIFO gets more page faults than LRU in every memory size bellow 7.
This also concludes an interesting fact, at n + 2 size(n being the number of different pages), both algorithms bring the same results. So in this case in which, n = 5, from 7 onwards the page faults in both LRU and FIFO will be the same providing the sequence is the same for both.
And that's all for the page replacement, if you have any doubt or observations, feel free to write in the comment section bellow.
References:
2nd Theoretical Assignment - TLB and Page Table
Paging
Another attribute of paging is its abstraction, which allows a logical address to point at a page even when the page is not in the range of addresses of the memory frames, this can take advantage of all the logical address space in the computer.
Page Table
The page table is a structure which performs the translation of logical addresses into physical addresses from the memory. Besides this, the page table keeps track of the pages, and improves the security of the pages, managing the writing, reading, and executing permissions
The most common fields in a page table are:
The address of the frame in memory
Presence bit used to know tell if the page is found.
The dirty bit used to know if a file has been modified in the main memory, and must be updated in secondary memory.
Persistence bit
Writing, reading and modification bit.
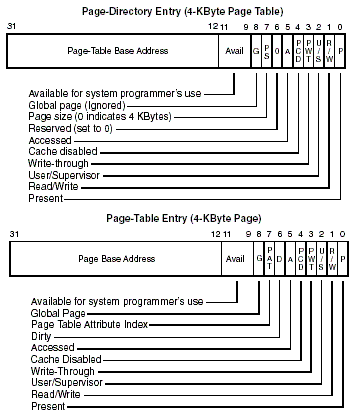
To translate logical addresses into physical addresses, the logical address is divided in the number of pages and the displacement, then the number of pages is used to find it inside the page table, once the address of the page is found , the displacement is added to the memory inside the page, and that's how the physical address is found.
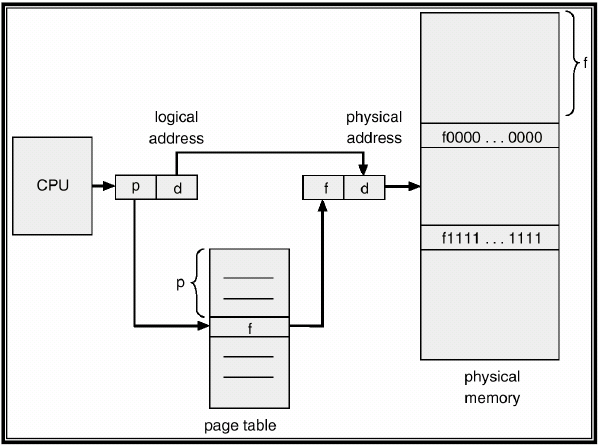
Despite the number of addresses managed with paging being decreased, the page tables can be extremely large, so different techniques are used to organize this tables.
Page Fault
If the presence bit in the memory marks that is not present in the main memory, the MMU responds by rising and exception(commonly called page fault). If the page is found in the swap space, the operating system will invoke an operation called page replacement, to bring the page required to the main memory. This operation takes several steps and it may be time-consuming.
TLB
Even if tables decreases the quantity of managed addresses, these can be very large and slow, so a cache memory is used. This memory can reside between the memory and the cache itself or between the cache and the main memory unit. This memory is very fast, but small. Typically the TLB has between 2 and 2048 entries. So, before accessing to the page table, the hardware looks in the TLB, if the logical address is there, so is the corresponding physical address and it's accessed directly. If it's not there, the hardware looks in the page table, and then the memory, and saves the access in the TLB
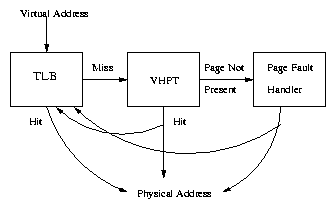
Algorithm for accessing a virtual address:
References:
http://nits.com.ar/uadeclasses/clase11.html
http://viralpatel.net/taj/tutorial/paging.php
http://www.pling.org.uk/cs/ops.html
http://es.wikipedia.org/wiki/Paginaci%C3%B3n_de_memoria
http://es.wikipedia.org/wiki/Translation_Lookaside_Buffer
http://expo.itch.edu.mx/view.php?f=os_42#page6
Organización de computadoras. Un enfoque estructurado, 4ta Edición - Andrew S. Tanenbaum
In the first computers, memories were reduced and normally programs wouldn't fit in them, slow algorithms were used, and to address this problem the memory was divided in pieces and secondary memories were used to load some of this pieces of processes into the main memory, and the others into a secondary memory for later use. This is called memory overlay.
Even so, this still brought many problems to programmers because they had to work with the address of the overlays which brought as consequence the idea of paging. Paging is a method to separate the memory space from addresses and addresses from memory in the main memory of the computers, this idea was came to be in 1961 from a group of researchers in Manchester, England.
In paging, the address space is divided in pieces, called pages and the physical memory is divided in pieces of the same size called frames which allows large spaces of memory to be reduced in small pieces.
An address space may feature a n quantity of bits which can address 2^n addresses. Dividing this address space in pieces decreases this number, which makes the administration of this address space more simple.
The address space is also divided, for example, if we have an address space of 32 bits, and frames of 4kb, which is equivalent to 2^12 physical memory addresses, the last 12 bits of the address are assigned to the addressing inside the frames, and the other 20 at the left, are assigned to the frame's address space, leaving 2^20 addresses managed by the operating system, doing a more lighter job.
0000 0000 0000 0000 0000 0000 0111 1111
|_____________________| |____________|
| |
| v
| Memory location within the page
v
Page Number
Another attribute of paging is its abstraction, which allows a logical address to point at a page even when the page is not in the range of addresses of the memory frames, this can take advantage of all the logical address space in the computer.
Page Table
The page table is a structure which performs the translation of logical addresses into physical addresses from the memory. Besides this, the page table keeps track of the pages, and improves the security of the pages, managing the writing, reading, and executing permissions
The most common fields in a page table are:
The address of the frame in memory
Presence bit used to know tell if the page is found.
The dirty bit used to know if a file has been modified in the main memory, and must be updated in secondary memory.
Persistence bit
Writing, reading and modification bit.
To translate logical addresses into physical addresses, the logical address is divided in the number of pages and the displacement, then the number of pages is used to find it inside the page table, once the address of the page is found , the displacement is added to the memory inside the page, and that's how the physical address is found.
Despite the number of addresses managed with paging being decreased, the page tables can be extremely large, so different techniques are used to organize this tables.
Page Fault
If the presence bit in the memory marks that is not present in the main memory, the MMU responds by rising and exception(commonly called page fault). If the page is found in the swap space, the operating system will invoke an operation called page replacement, to bring the page required to the main memory. This operation takes several steps and it may be time-consuming.
TLB
Even if tables decreases the quantity of managed addresses, these can be very large and slow, so a cache memory is used. This memory can reside between the memory and the cache itself or between the cache and the main memory unit. This memory is very fast, but small. Typically the TLB has between 2 and 2048 entries. So, before accessing to the page table, the hardware looks in the TLB, if the logical address is there, so is the corresponding physical address and it's accessed directly. If it's not there, the hardware looks in the page table, and then the memory, and saves the access in the TLB
Algorithm for accessing a virtual address:
- The MMU receives from the CPU a dir -virtual.
- MMU searches( in parallel) dir -virtual in the TLB memory. If it's successful go to step 7.
- Search the address in the page table. If it's successful go to step 6, if else, generate a page fault.
- Execute a strategy of page replacement
- Swap pages between disk-memory
- Delete the TLB and update the page table.
- Update the TLB
- Generate a physical address and search for data in memory. If it's not successful, consult for data in the page table.
- MMU returns the requested data.
References:
http://nits.com.ar/uadeclasses/clase11.html
http://viralpatel.net/taj/tutorial/paging.php
http://www.pling.org.uk/cs/ops.html
http://es.wikipedia.org/wiki/Paginaci%C3%B3n_de_memoria
http://es.wikipedia.org/wiki/Translation_Lookaside_Buffer
http://expo.itch.edu.mx/view.php?f=os_42#page6
Organización de computadoras. Un enfoque estructurado, 4ta Edición - Andrew S. Tanenbaum
Suscribirse a:
Entradas (Atom)